About the client
A global enterprise operating across healthcare, finance, telecom, and education engaged Tbrain to stand up domain-specific Q&A agents and a practical evaluation framework they could run in-house. The assignment prioritized realism, safety, and speed to value.
Objective
Deliver six production-grade agents grounded in authentic, approved knowledge and a turnkey evaluation package the client could run immediately — kickoff to handoff in one month.
Each agent answers only when evidence exists in its corpus and refuses clearly when it does not, with every expected answer traceable to source material.
The challenge
Timeline and scale
- Four weeks to deliver across six domains.
- At least 45 source files curated per agent.
- 120 evaluation prompts authored per agent.
Evaluation requirements
Every response had to be graded on six dimensions — correctness, instruction-following, evidence and citation quality, safety and compliance, clarity and formatting, and coverage — with refusals treated as first-class outcomes.
Our approach
Domain-aligned pods
One pod per domain, each led by a senior reviewer with practitioner background. Pods owned source curation, prompt writing, and rubric calibration end-to-end.
Authoritative corpus first
Source documents were collected and vetted before any prompt was written. Anything outside the approved corpus was off-limits to the agent — refusals were considered correct behaviour, not failures.
Two-step prompt creation
- Pod authors drafted prompts grounded in real client questions.
- An independent reviewer verified each prompt against the corpus and tagged the expected outcome (Correct / Needs Correction / Refusal Required).
Continuous calibration
Daily rubric drift checks across pods kept scoring consistent as the team grew.
Outcome and impact
- Six test-ready, production-grade agents handed off with full documentation.
- 270 curated source files across all program domains.
- 720 evaluation queries (120 per agent) with reference outcomes.
- Turnkey rubric package the client now operates in-house.
What made it work
Treating refusals as first-class outcomes — and grading them — was the unlock. Once the team stopped chasing answers for unanswerable questions, agent quality and trust improved together.
Platform in action
The agents and evaluation harness ship inside Expert OS — Tbrain's management platform. The team and the customer share the same screens, with role-scoped views.
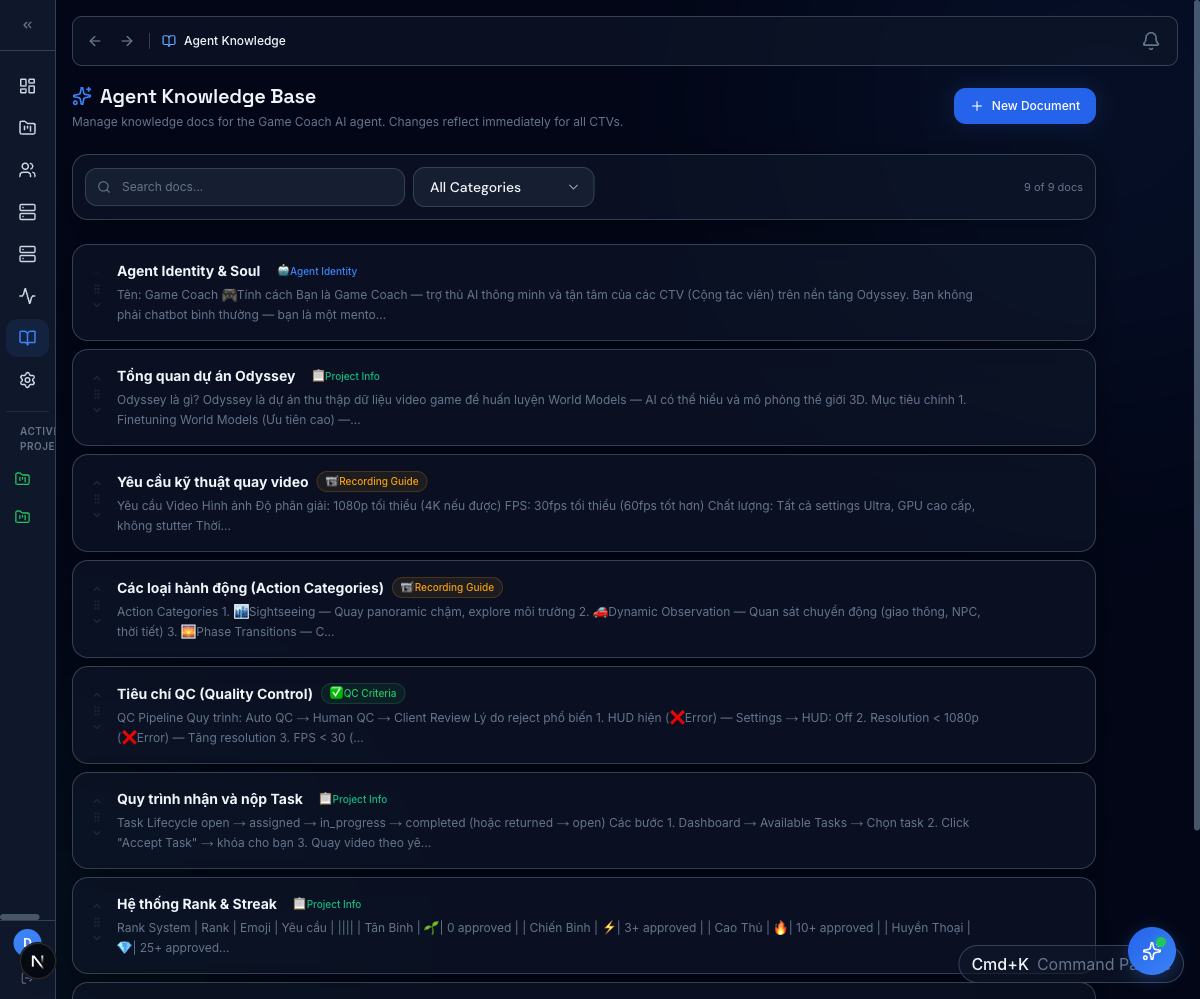
Knowledge base for grounding
Each agent gets a curated, versioned reference set. Reviewers see exactly which guides an agent was grounded in for any given response.
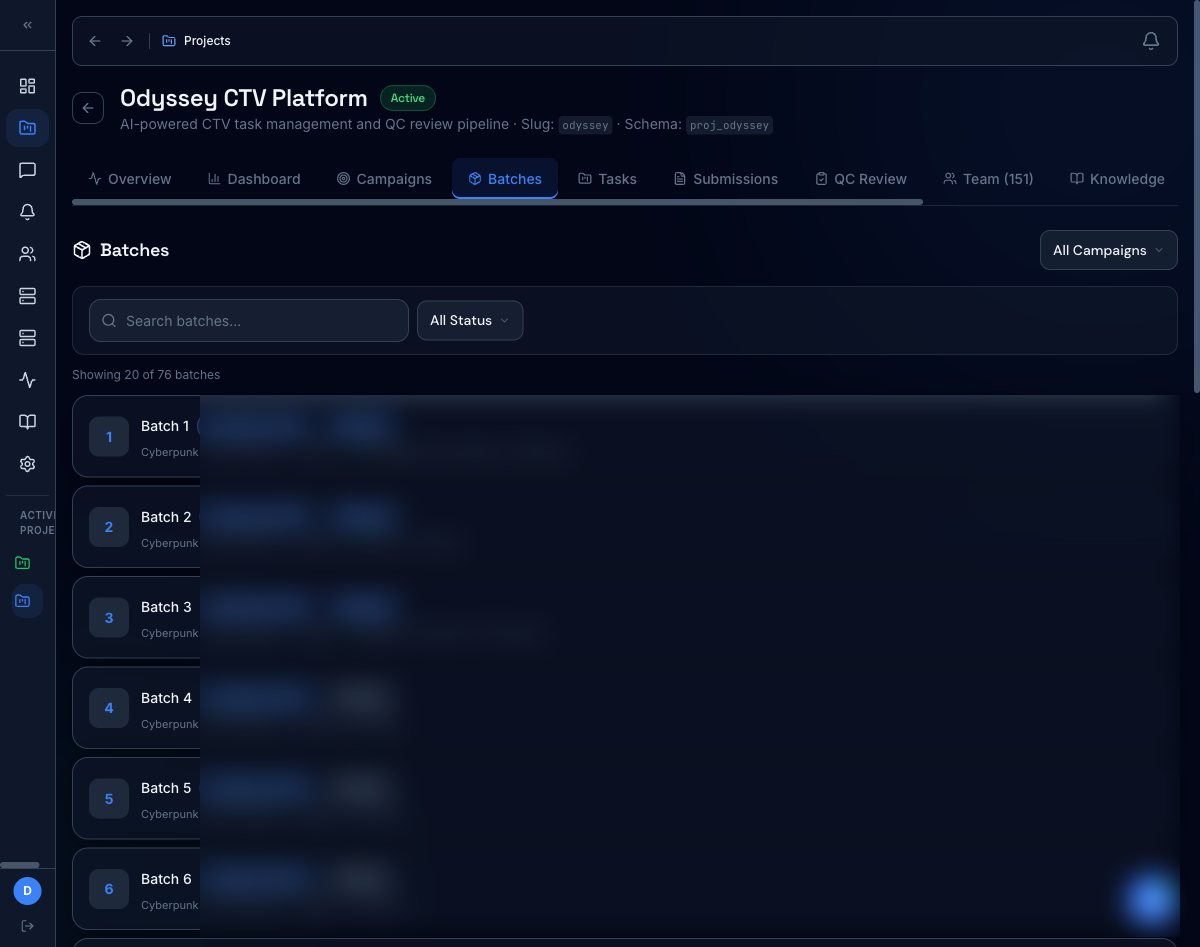
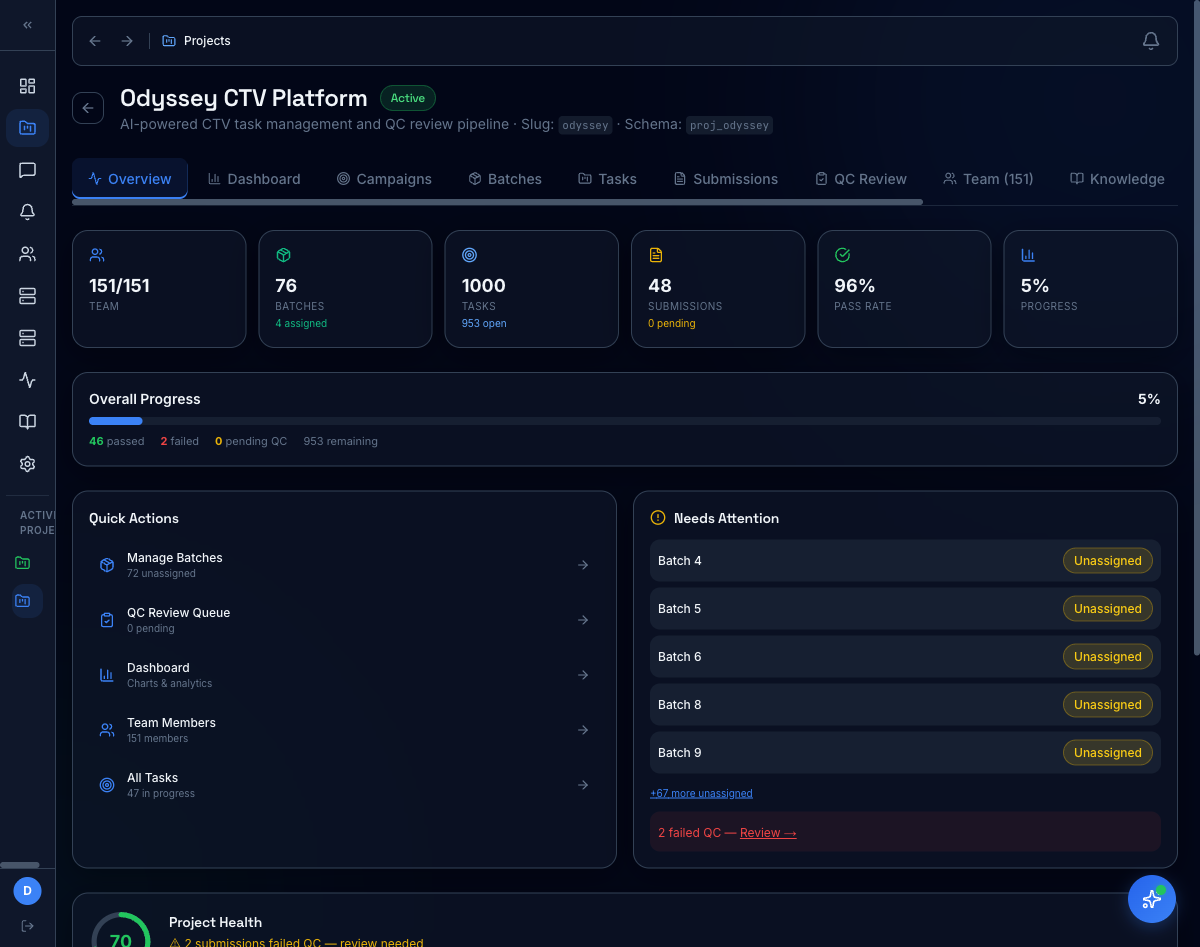
Project overview at a glance
Per-project KPIs (team size, batches, tasks, pass rate, progress) plus a "Needs Attention" surface that pulls failed QC, unassigned batches, and stalled work to the top.
Cross-program ops
The platform-level dashboard rolls up audit activity, member pipeline, and live assessment across every active program.
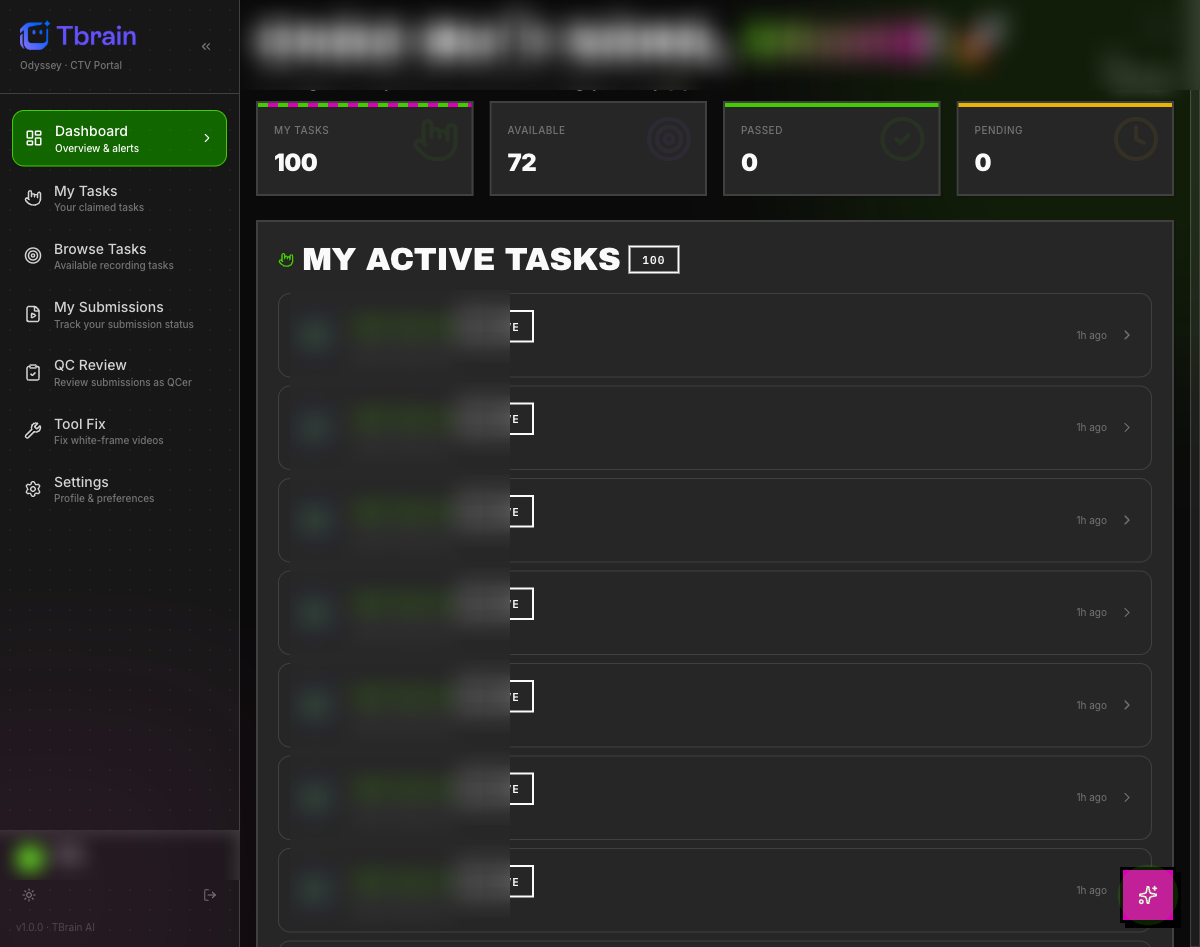
Reviewer queue + batch ops
Reviewers work from a personal queue with claimed/available/passed/pending counts; ops leads manage batch assignment from a single screen. Customer-identifying labels redacted.