The challenge
The customer needed 500+ multi-step reasoning tasks validated by domain experts in under 90 days.
Our approach
We assembled a four-layer review pipeline: SME drafting, peer review, automated grading, and final calibration.
- 4-layer human + LLM review.
- Custom annotation tool with audit trail.
- Daily QA reports.
Outcome
500 production-ready tasks delivered, with 92% inter-annotator agreement.
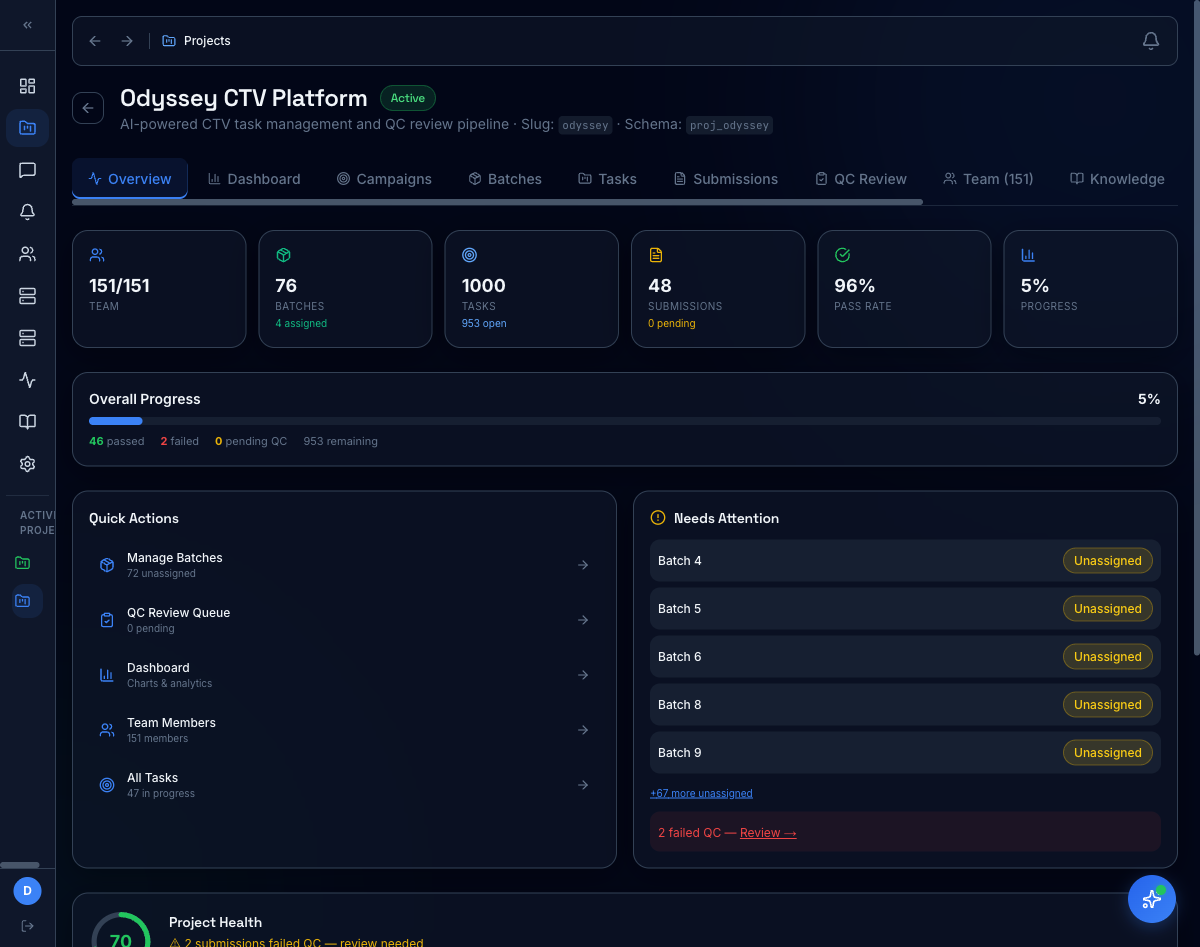
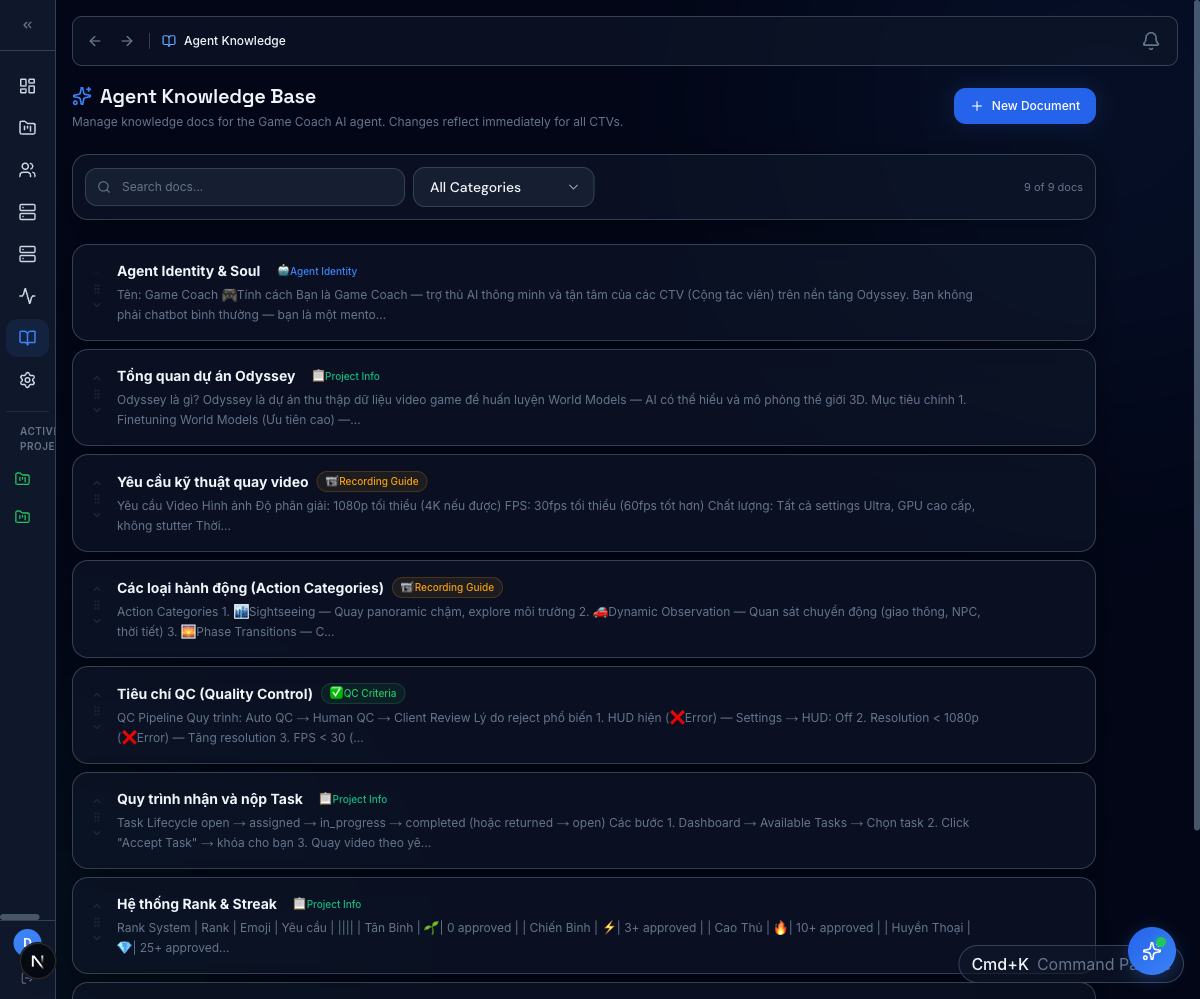
Platform in action
Every reasoning task lives inside Expert OS — the same platform our reviewers, QC pods, and program leads use day to day. Customers can browse the catalog, drill into any task, and audit the QC trail.